Distributed Tracing
With distributed tracing, you can get a connected view of your application from the frontend to the backend. You'll be able to track your software performance, measure metrics like throughput and latency, and display the impact of errors across multiple systems. Distributed tracing makes Sentry a more complete performance monitoring solution, helping you diagnose problems and measure your application's overall health more quickly. Tracing in Sentry provides insights such as:
- What occurred for a specific error event or issue
- The conditions that cause bottlenecks or latency issues in your application
- The endpoints or operations that consume the most time
To begin, a note about what tracing is not: Tracing is not profiling. Though the goals of profiling and tracing overlap quite a bit, and though they can both be used to diagnose problems in your application, they differ in terms of what they measure and how the data is recorded.
A profiler may measure any number of aspects of an application's operation: the number of instructions executed, the amount of memory being used by various processes, the amount of time a given function call takes, and many more. The resulting profile is a statistical summary of these measurements.
A tracing tool, on the other hand, focuses on what happened (and when), rather than how many times it happened or how long it took. The resulting trace is a log of events which occurred during a program's execution, often across multiple systems. Though traces most often - or, in the case of Sentry's traces, always - include timestamps, allowing durations to be calculated, measuring performance is not their only purpose. They can also show the ways in which interconnected systems interact, and the ways in which problems in one can cause problems in another.
Applications typically consist of interconnected components, which are also called services. As an example, let's look at a modern web application, composed of the following components, separated by network boundaries:
- Frontend (Single-Page Application)
- Backend (REST API)
- Task Queue
- Database Server
- Cron Job Scheduler
Each of these components may be written in a different language on a different platform. Each can be instrumented individually using a Sentry SDK to capture error data or crash reports, but that instrumentation doesn't provide the full picture, as each piece is considered separately. Tracing allows you to tie all of the data together.
In our example web application, tracing means being able to follow a request from the frontend to the backend and back, pulling in data from any background tasks or notification jobs that request creates. Not only does this allow you to correlate Sentry error reports, to see how an error in one service may have propagated to another, but it also allows you to gain stronger insights into which services may be having a negative impact on your application's overall performance.
Before learning how to enable tracing in your application, it helps to understand a few key terms and how they relate to one another.
A trace represents the record of the entire operation you want to measure or track - like page load, an instance of a user completing some action in your application, or a cron job in your backend. When a trace includes work in multiple services, such as those listed above, it's called a distributed trace, because the trace is distributed across those services.
Each trace consists of one or more tree-like structures called transactions, the nodes of which are called spans. In most cases, each transaction represents a single instance of a service being called, and each span within that transaction represents that service performing a single unit of work, whether calling a function within that service or making a call to a different service. Here's an example trace, broken down into transactions and spans:
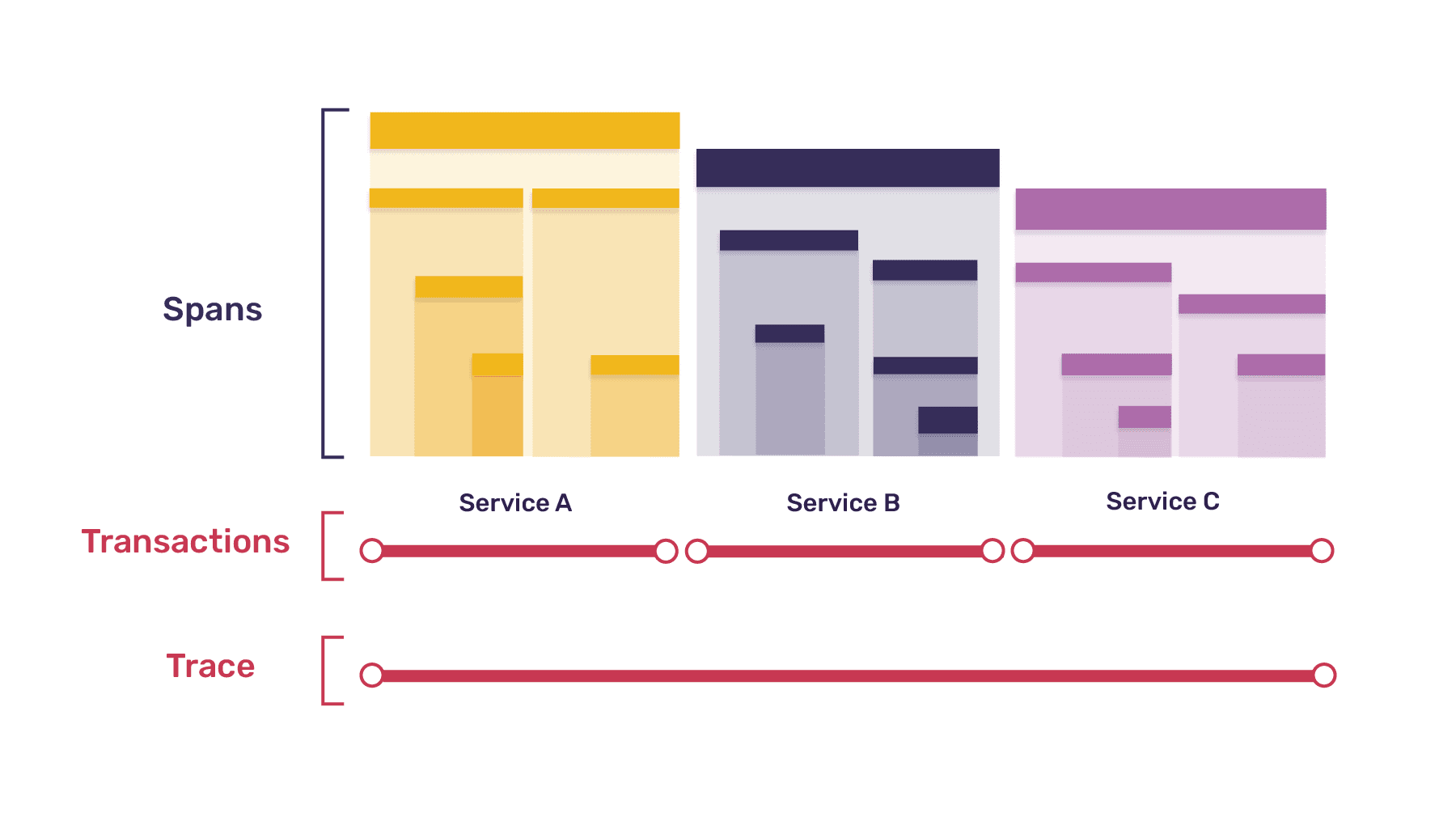
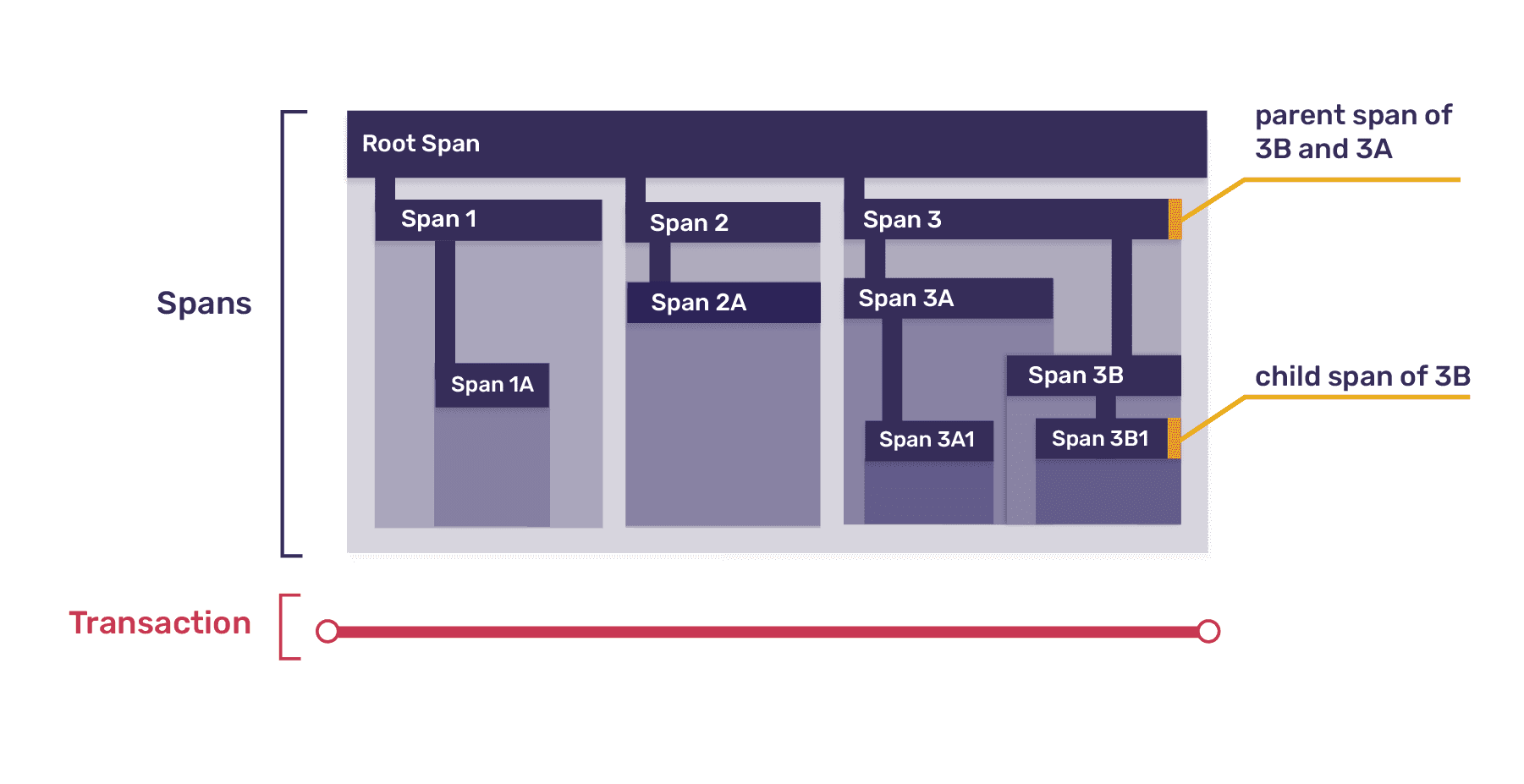
Because a transaction has a tree structure, top-level spans can themselves be broken down into smaller spans, mirroring the way that one function may call a number of other, smaller functions; this is expressed using the parent-child metaphor, so that every span may be the parent span to multiple other child spans. Further, since all trees must have a single root, one span in every transaction always represents the transaction itself, with all other spans in the transaction descending from that root span. Here's a zoomed-in view of one of the transactions from the diagram above:
To make all of this more concrete, let's consider our example web app again.
Suppose your web application is slow to load, and you'd like to know why. A lot has to happen for your app to first get to a usable state: multiple requests to your backend, likely some work - including calls to your database or to outside APIs - completed before responses are returned, and processing by the browser to render all of the returned data into something meaningful to the user. So which part of that process is slowing things down?
Let's say, in this simplified example, that when a user loads the app in their browser, the following happens in each service:
- Browser
- 1 request each for HTML, CSS, and JavaScript
- 1 rendering task, which sets off 2 requests for JSON data
- Backend
- 3 requests to serve static files (the HTML, CSS, and JS)
- 2 requests for JSON data - 1 requiring a call to the database - 1 requiring a call to an external API and work to process the results before returning them to the frontend
- Database Server
- 1 request which requires 2 queries
- 1 query to check authentication
- 1 query to get data
- 1 request which requires 2 queries
Note: The external API is not listed precisely because it's external, and you therefore can't see inside of it.
In this example, the entire page-loading process, including all of the above, is represented by a single trace. That trace would consist of the following transactions:
- 1 browser transaction (for page load)
- 5 backend transactions (one for each request)
- 1 database server transaction (for the single DB request)
Each transaction would be broken down into spans as follows:
- Browser Page-load Transaction: 7 spans
- 1 root span representing the entire page load
- 1 span each (3 total) for the HTML, CSS, and JS requests
- 1 span for the rendering task, which itself contains
- 2 child spans, one for each JSON request
Let's pause here to make an important point: Some, though not all, of the spans listed here in the browser transaction have a direct correspondence to backend transactions listed earlier. Specifically, each request span in the browser transaction corresponds to a separate request transaction in the backend. In this situation, when a span in one service gives rise to a transaction in a subsequent service, we call the original span a parent span to both the transaction and its root span. In the diagram below, the squiggly lines represent this parent-child relationship.
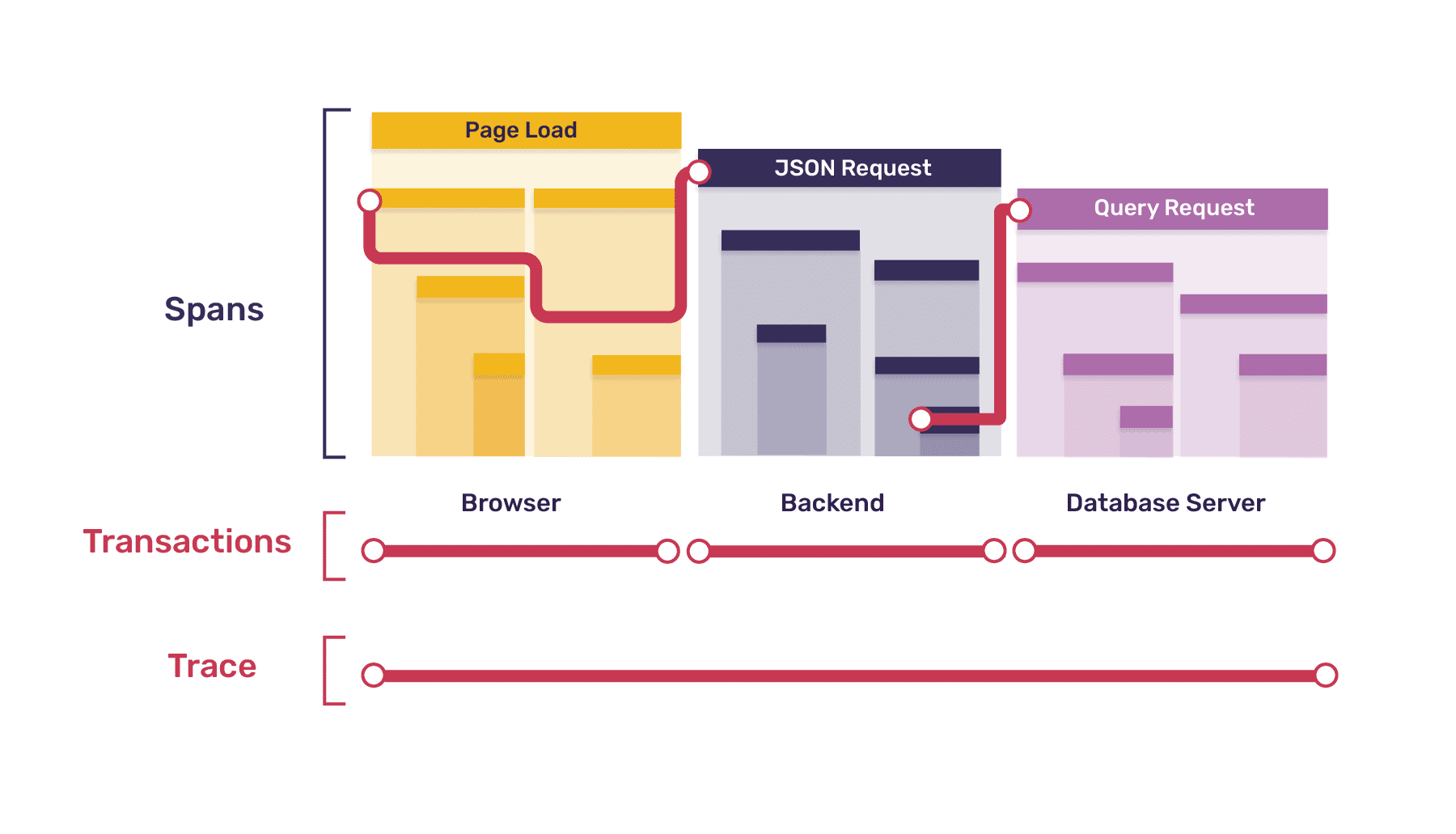
In our example, every transaction other than the initial browser page-load transaction is the child of a span in another service, which means that every root span other than the browser transaction root has a parent span (albeit in a different service).
In a fully-instrumented system (one in which every service has tracing enabled) this pattern will always hold true. The only parentless span will be the root of the initial transaction; every other span will have a parent. Further, parents and children will always live in the same service, except in the case where the child span is the root of a child transaction, in which case the parent span will live in the calling service and the child transaction/child root span will live in the called service.
Put another way, a fully-instrumented system creates a trace which is itself a connected tree - with each transaction a subtree - and in that tree, the boundaries between subtrees/transactions are precisely the boundaries between services. The diagram above shows one branch of our example's full trace tree.
Now, for the sake of completeness, back to our spans:
- Backend HTML/CSS/JS Request Transactions: 1 span each
- 1 root span representing the entire request (child of a browser span)
- Backend Request with DB Call Transaction: 2 spans
- 1 root span representing the entire request (child of a browser span)
- 1 span for querying the database (parent of the database server transaction)
- Backend Request with API Call Transaction: 3 spans
- 1 root span representing the entire request (child of a browser span)
- 1 span for the API request (unlike with the DB call, not a parent span, since the API is external)
- 1 span for processing the API data
- Database Server Request Transaction: 3 spans
- 1 root span representing the entire request (child of the backend span above)
- 1 span for the authentication query
- 1 span for the query retrieving data
To wrap up the example: after instrumenting all of your services, you might discover that - for some reason - it's the auth query in your database server that is making things slow, accounting for more than half of the time it takes for your entire page load process to complete. Tracing can't tell you why that's happening, but at least now you know where to look!
This section contains a few more examples of tracing, broken down into transactions and spans.
If your application involves e-commerce, you likely want to measure the time between a user clicking "Submit Order" and the order confirmation appearing, including tracking the submitting of the charge to the payment processor and the sending of an order confirmation email. That entire process is one trace, and typically you'd have transactions (T) and spans (S) for:
- The browser's full process (T and root span S)
- XHR request to backend* (S)
- Rendering confirmation screen (S)
- Your backend's processing of that request (T and root span S)
- Function call to compute total (S)
- DB call to store order* (S)
- API call to payment processor (S)
- Queuing of email confirmation* (S)
- Your database's work updating the customer's order history (T and root span S)
- Individual SQL queries (S)
- The queued task of sending the email (T and root span S)
- Function call to populate email template (S)
- API call to email-sending service (S)
* Starred spans represent spans that are the parent of a later transaction (and its root span).
If your backend periodically polls for data from an external service, processes it, caches it, and then forwards it to an internal service, each instance of this happening is a trace, and you'd typically have transactions (T) and spans (S) for:
- The cron job that completes the entire process (T and root span S)
- API call to external service (S)
- Processing function (S)
- Call to caching service* (S)
- API call to internal service* (S)
- The work done in your caching service (T and root span S)
- Checking cache for existing data (S)
- Storing new data in cache (S)
- Your internal service's processing of the request (T and root span S)
- Anything that service might do to handle the request (S)
* Starred spans represent spans that are the parent of a later transaction (and its root span).
"Show me your flowchart and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won't usually need your flowchart; it'll be obvious."
-- Fred Brooks, The Mythical Man Month (1975)
While the theory is interesting, ultimately any data structure is defined by the kind of data it contains, and relationships between data structures are defined by how links between them are recorded. Traces, transactions, and spans are no different.
Traces are not an entity in and of themselves. Rather, a trace is defined as the collection of all transactions that share a trace_id value.
Transactions share most of their properties (start and end time, tags, and so forth) with their root spans, so the same options described below for spans are available in transactions, and setting them in either place is equivalent.
Transactions also have one additional property not included in spans, called transaction_name, which is used in the UI to identify the transaction. Common examples of transaction_name values include endpoint paths (like /store/checkout/ or api/v2/users/<user_id>/) for backend request transactions, task names (like data.cleanup.delete_inactive_users) for cron job transactions, and URLs (like https://docs.sentry.io/performance-monitoring/distributed-tracing/) for page-load transactions.
Transaction names can potentially contain sensitive data. See Scrubbing Sensitive Data for more information.
Note: Before the transaction is sent, the tags and data properties will get merged with data from the global scope. (Global scope data is set either in Sentry.init() - for things like environment and release - or by using Sentry.configureScope(), Sentry.setTag(), Sentry.setUser(), and Sentry.setExtra().
The majority of the data in a transaction resides in the individual spans the transaction contains. Span data includes:
parent_span_id: ties the span to its parent spanop: short string identifying the type or category of operation the span is measuring. Details on the structure of span operations can be found in the Sentry developer documentation.start_timestamp: when the span was openedend_timestamp: when the span was closeddescription: longer description of the span's operation, which uniquely identifies the span but is consistent across instances of the span (optional)status: short code indicating operation's status (optional)tags: key-value pairs holding additional data about the span (optional)data: arbitrarily-structured additional data about the span (optional)
An example use of the op and description properties together is op: db.query and description: SELECT * FROM users WHERE last_active < %s. The status property is often used to indicate the success or failure of the span's operation, or for a response code in the case of HTTP requests. Finally, tags and data allow you to attach further contextual information to the span, such as function: middleware.auth.is_authenticated for a function call or request: {url: ..., headers: ... , body: ...} for an HTTP request.
A few more important points about traces, transactions, and spans, and the way they relate to one another:
Because a trace is just a collection of transactions, traces don't have their own start or end times. A trace begins when the earliest transaction it registers starts, and ends when the latest transaction it registers ends. So while you can't "start" or "end" a trace, you can initiate a transaction which will then trigger a trace. And you can end a trace by completing all of the transactions it would be registering.
Because of the possibility of asynchronous processes, child transactions may outlive the transactions containing their parent spans, sometimes by many orders of magnitude. For example, if a backend API call sets off a long-running processing task and then immediately returns a response, the backend transaction will finish (and its data will be sent to Sentry) long before the async task transaction does. Asynchronicity also means that the order in which transactions are sent to (and received by) Sentry does not in any way depend on the order in which they were created. (By contrast, order of receipt for transactions in the same trace is correlated with order of completion, though because of factors like the variability of transmission times, the correlation is far from perfect.)
In theory, in a fully instrumented system, each trace should contain only one transaction and one span (the transaction's root) without a parent, namely the transaction in the originating service. However, in practice, you may not have tracing enabled in every one of your services, or an instrumented service may fail to report a transaction due to network disruption or other unforeseen circumstances. When this happens, you may see gaps in your trace hierarchy. Specifically, you may see transactions partway through the trace whose parent spans haven't been recorded as part of any known transactions. Such non-originating, parentless transactions are called orphan transactions.
Though our examples above had four levels in their hierarchy (trace, transaction, span, child span) there's no set limit to how deep the nesting of spans can go. There are, however, practical limits: transaction payloads sent to Sentry have a maximum allowed size, and as with any kind of logging, there's a balance to be struck between your data's granularity and its usability.
It's possible for a span to have equal start and end times, and therefore be recorded as taking no time. This can occur either because the span is being used as a marker (such as is done in the browser's Performance API) or because the amount of time the operation took is less than the measurement resolution (which will vary by service).
If you are collecting transactions from multiple machines, you will likely encounter clock skew, where timestamps in one transaction don't align with timestamps in another. For example, if your backend makes a database call, the backend transaction logically should start before the database transaction does. But if the system time on each machine (those hosting your backend and database, respectively) isn't synced to a common standard, it's possible that won't be the case. It's also possible for the ordering to be correct, but for the two recorded timeframes to not line up in a way that accurately reflects what actually happened. To reduce this possibility, we recommend using Network Time Protocol (NTP) or your cloud provider's clock synchronization services.
Individual spans aren't sent to Sentry; rather, the entire transaction is sent as one unit. This means that no span data will be recorded by Sentry's servers until the transaction to which they belong is closed and dispatched. The converse is not true, however - though spans can't be sent without a transaction, transactions are still valid, and will be sent, even if the only span they contain is their root span.
When you enable sampling in your tracing setup, you choose a percentage of collected transactions to send to Sentry. For example, if you had an endpoint that received 1000 requests per minute, a sampling rate of 0.25 would result in approximately 250 transactions (25%) being sent to Sentry each minute. (The number is approximate because each request is either tracked or not, independently and pseudorandomly, with a 25% probability. So in the same way that 100 fair coins, when flipped, result in approximately 50 heads, the SDK will "decide" to collect a trace in approximately 250 cases.) Because you know the sampling percentage, you can then extrapolate your total traffic volume.
When collecting traces, we recommend sampling your data, for two reasons. First, though capturing a single trace involves minimal overhead, capturing traces for every single page load, or every single API request, has the potential to add an undesirable amount of load to your system. Second, enabling sampling allows you to better manage the number of events sent to Sentry, so you can tailor it to your organization's needs.
When choosing a sampling rate, the goal is to not collect too much data (given the reasons above) but also to collect enough data that you are able to draw meaningful conclusions. If you're not sure what rate to choose, we recommend starting with a low value and gradually increasing it as you learn more about your traffic patterns and volume, until you've found a rate which lets you balance performance and volume concerns with data accuracy.
For traces that involve multiple transactions, Sentry uses a "head-based" approach: a sampling decision is made in the originating service, and then that decision is passed to all subsequent services. To see how this works, let's return to our webapp example above. Consider two users, A and B, who are both loading your app in their respective browsers. When A loads the app, the SDK pseudorandomly "decides" to collect a trace, whereas when B loads the app, the SDK "decides" not to. When each browser makes requests to your backend, it includes in those requests the "yes, please collect transactions" or the "no, don't collect transactions this time" decision in the headers.
When your backend processes the requests from A's browser, it sees the "yes" decision, collects transaction and span data, and sends it to Sentry. Further, it includes the "yes" decision in any requests it makes to subsequent services (like your database server), which similarly collect data, send it to Sentry, and pass the decision along to any services they call. Through this process, all of the relevant transactions in A's trace are collected and sent to Sentry.
On the other hand, when your backend processes the requests from B's browser, it sees the "no" decision, and as a result it does not collect and send transaction and span data to Sentry. It does, however, do the same thing it does in A's case in terms of propagating the decision to subsequent services, telling them not to collect or send data either. They then in turn tell any services they call not to send data, and in this way no transactions from B's trace are collected.
Put simply: as a result of this head-based approach, where the decision is made once in the originating service and passed to all subsequent services, either all of the transactions for a given trace are collected, or none are, so there shouldn't be any incomplete traces.
Through Performance and Discover, you can view trace data in the event details.
Our documentation is open source and available on GitHub. Your contributions are welcome, whether fixing a typo (drat!) or suggesting an update ("yeah, this would be better").